
文字の符号化(エンコーディング)とは、人間が使う文字や記号を、コンピュータが理解・処理できる2進数(バイト列)のデータに変換する仕組みのことです。文字を数値に対応させる「文字コード」と、その具体的な変換ルール「文字符号化方式」により、データ保存や通信を実現します。
画像参照:https://jiji.blog/what-is-character-encoding/
基本概念
文字の符号化に関する詳細と重要なポイントは以下の通りです。
符号化の基本概念
- 目的: コンピュータは数字しか扱えないため、文字を固有の数値に対応させる必要がある。
- エンコード: 文字をデータに変換すること。
- デコード: 符号化されたデータを元に戻すこと。
重要な構成要素
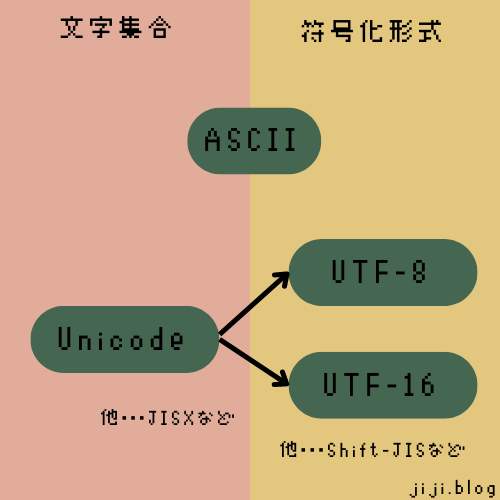
文字コードの世界では、主に2つの概念が組み合わさっています。
- 符号化文字集合 (CCS): 文字に番号(識別番号)を割り振るルール。例: Unicode, JIS X 0208。
- 文字符号化方式 (CES): その番号を実際の「バイト列」にどう変換するかのルール。例: UTF-8, Shift_JIS。
文字コード
代表的な文字コードを下記に整理します。
| 名称 | 特徴 |
|---|---|
| ASCII(アスキー) | アルファベット、数字、一部の記号、制御文字(改行など)を7ビットで表現し、128種類の文字を定義しており、インターネットの基盤として広く使われています。 |
| JIS | 7ビット単位の符号化を行い、主に電子メールやネットニュースなどの通信規格(SMTPなど)で標準として使用されてきた、歴史ある文字コードです。 |
| Shift_JIS (SJIS) | 半角(英数字・カナ)を1バイト、全角(漢字・ひらがな)を2バイトで表現し、1バイト目で文字の幅を判別できるため、処理効率が高いのが特徴です。 |
| Unicode(ユニコード) | 世界中のほぼすべての言語、文字、絵文字に一意の数字(コードポイント)を割り当てる国際的な文字コード標準です。 |
| EUC | 1文字を基本的に2バイト(補助漢字は3バイト)で表現し、主に過去のLinuxやWebアプリケーションで標準的に利用された、ISO/IEC 2022に準拠した符号化方式です。 |
ASCII
ASCII(アスキー)コードは、英数字や記号、制御文字を0~127の7ビットで表現する米国の標準文字コード(計128種類)です。大文字・小文字のアルファベット、数字、スペース、改行コードなどを収録し、多くの文字コード(UTF-8など)の基礎となっています。16進数では00〜7Fの範囲で表現されます。
主な特徴
- 7ビット表現:0〜127(27=128
通り)の数値で文字を定義。
- 収録文字: 半角英数字(A-Z, a-z, 0-9)、スペース、符号(!, “, #, $…)、および制御文字(改行やタブ)。
- 文字コードの基礎: UTF-8やISO-8859-1などの互換性を持つ基盤規格。
- 非対応文字: 日本語(ひらがな、漢字、全角文字)、アクセント記号付きの文字などは含まれない。
主要なASCIIコード表(16進数)
| 文字 | 16進数 | 10進数 |
|---|---|---|
| スペース | 20 | 32 |
0~9 | 30~39 | 48~57 |
A~Z | 41~5A | 65~90 |
a~z | 61~7A | 97~122 |
! | 21 | 33 |
@ | 40 | 64 |
DEL | 7F | 127 |
補足
- ASCIIとISO 646: 日本のJIS X 0201(半角カナ含む)などは、このASCIIを拡張して8ビット(256文字)にしたもの。
- 8ビット環境: コンピュータでは1バイト(8ビット)単位で管理されるため、上位1ビットを0にした7ビット形式で扱われる。
JIS
JISコード(ISO-2022-JP)は、日本産業規格(JIS)で定められた、コンピュータで日本語を扱うための初期の文字コード体系です。7ビット単位の符号化を行い、主に電子メールやネットニュースなどの通信規格(SMTPなど)で標準として使用されてきた、歴史ある文字コードです。
主な特徴
- 用途: 主にメール(ISO-2022-JP)で利用。半角英数字、全角の漢字・ひらがな・カタカナを記述可能。
- 仕組み: 「エスケープシーケンス」と呼ばれる特殊な制御文字を用いて、英数モードと漢字モードを切り替える。
- 特徴: 7ビットデータであるため、古くからある通信システムでも文字化けしにくい。
- 注意点: 半角カタカナは利用できない。
関連する文字コード
- Shift_JIS (SJIS): Windowsなどで使われる、エスケープシーケンスを使わない符号化方式。
- EUC-JP: Unix系OSなどで使われていた符号化方式。
- Unicode (UTF-8): 現在の主流。JISに代わり広く使われている。
現在では多くのWebサービスやメールがUTF-8へ移行していますが、レガシーなシステムとの連携や古いメールデータの取り扱いにおいて、JISコードが使われる場面はまだ存在します。
Shift_JIS
Shift_JIS(シフトジス)は、主にWindows環境や日本のレガシーシステムで普及している日本語文字コード規格(ANSI/SJIS)です。半角英数字を1バイト、全角文字を2バイトで表現し、1バイト目で文字の種類(全角/半角)を判別する特徴があります。現在ではUTF-8への移行が進んでいますが、Windowsや古い印刷データで利用されています。
主な特徴と情報
- 特徴: JISコードをベースに、8ビットコードの空き領域(0x80〜0x9F, 0xE0〜0xFC)へ文字を配置し、1バイト目だけで文字の全角・半角を判別可能にしました。
- 構造: 半角英数字は1バイト、漢字・ひらがな・全角カナは2バイト。
- 普及の背景: Microsoft社がMS-DOSなどで採用し、Windowsの標準コードとして普及しました。
- 派生・注意点: Windows環境で拡張されたWindows-31J(MS932)と混同されやすいですが、Shift_JIS(JIS X 0208)はそれよりも定義範囲が狭いです。
- 文字化けの原因: 2バイト目に特殊文字(
\や")のコードが入ることで、プログラムがエスケープ文字と誤認識し文字化けすることがあります。 - 現在: Webや現代のシステムでは世界標準のUTF-8が主流であり、互換性上の問題から使用は縮小傾向にあります。
0xとは
コンピュータ分野、特にプログラミングや技術的な文脈において、その後に続く数値が「16進数」であることを示す接頭辞です。
Unicode
Unicodeは、世界中のほぼすべての言語、文字、絵文字に一意の数字(コードポイント)を割り当てる国際的な文字コード標準です。文字化けを防ぎ、異なるプラットフォーム間でのデータ互換性を高めるため、現代のWebやOS(Windows, macOS, Linux, Java, .NETなど)で標準的に採用されています。
概要と重要ポイント
- 目的: 全世界の文字を統一的に表現し、国際的なアプリケーション開発を容易にする。
- 構造: 各文字は「U+XXXX」(16進数)形式のコードポイントで識別される。
- 文字エンコーディング(符号化方式):
- UTF-8: Webで最も一般的な可変長エンコーディング。英数字は1バイト、日本語などは3〜4バイト。
- UTF-16: 多くのOS内部処理で使用される。16ビット(2バイト)または32ビット(4バイト)。
- 特徴: 絵文字、歴史的な文字、数学記号なども収録。
- メリット: 多言語対応、高い互換性、将来的な拡張性(新たな文字の追加が可能)。
Unicodeは、ASCIIやISO-8859-1との互換性を確保しつつ、100万以上の文字を定義可能な設計がなされています。
EUC
EUC-JP(日本語EUC)は、AT&T社が策定したUNIXシステム向けの文字コード体系(Extended Unix Code)の日本語版。1文字を基本的に2バイト(補助漢字は3バイト)で表現し、主に過去のLinuxやWebアプリケーションで標準的に利用された、ISO/IEC 2022に準拠した符号化方式である。
主な特徴と仕様
- 文字構成: 英数字(1バイト)と漢字・ひらがな・全角カタカナ(2バイト、一部3バイト)を混在可能。
- 構造: JISコード(ISO-2022-JP)の各バイトの最上位ビットを1(
を加算)にした構造。
- コード領域:
- 1バイト目:
0xA1~
0xFE(制御コード・ASCIIを除く)。
- 2バイト目:
oxA1~
0xFE。
- 半角カタカナ:
0x8E(補助バイト)+ 0xA1
~0xDF。
- 補助漢字: 0x8F(補助バイト)+ 2バイト。
- 1バイト目:
- 用途: 歴史的にUNIX上のメールやWebシステム(CGI)で使用されたが、現在はUTF-8への移行が進んでいる。
- SJISとの違い: シフトJISはWindows環境で一般的だが、EUC-JPとは符号化方式に互換性がない。
EUC-JPは、JIS X 0208-1990(漢字)やJIS X 0212-1990(補助漢字)、半角カナを包括的に扱えるコードセットとして設計された。

コメント