
正規化とは、データや情報を一定のルールに基づいて整理・変換し、一貫性を持たせたり、扱いやすくしたりする手法です。データベース(RDB)における冗長性の排除や、機械学習におけるデータの0-1スケーリング(範囲補正)など、分野により意味が異なります。
データの重複を排除し、不整合(更新漏れなど)を防ぐために表(テーブル)を分割する設計手法です。
- 目的: データの不整合削減、メンテナンス性向上。
- 段階:
- 第1正規化: 繰り返し項目(セル結合など)の排除。
- 第2正規化: 部分関数従属(複合主キーの一部に依存する列)の解消。
- 第3正規化: 推移的関数従属(主キー以外に依存する列)の解消。
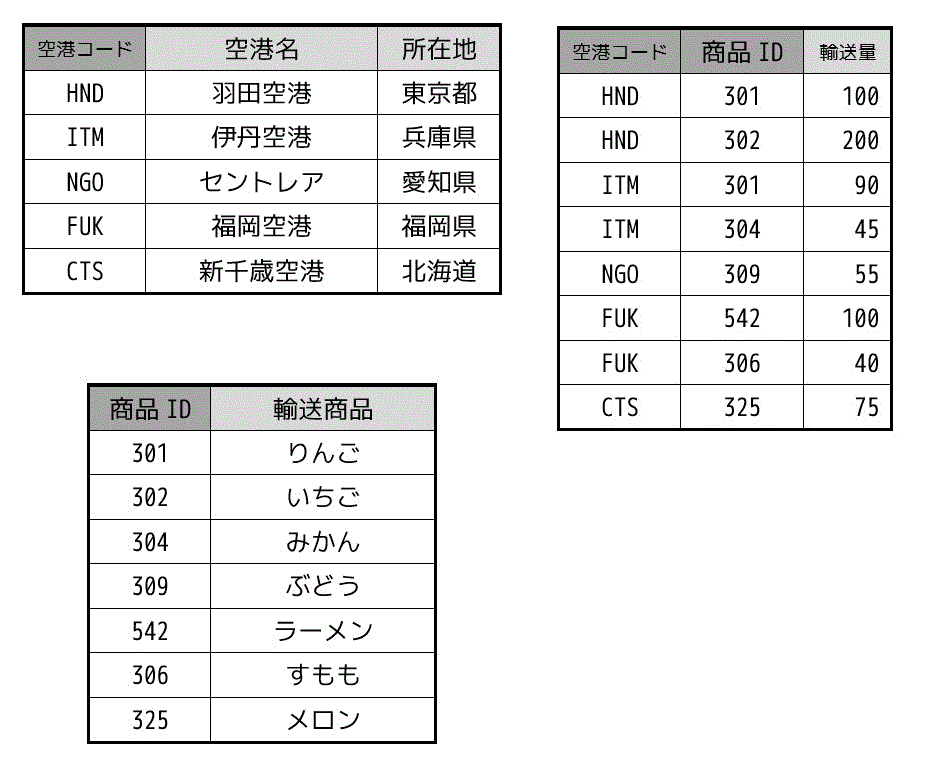
画像参照:https://www.momoyama-usagi.com/entry/info-database-seikika
関数従属
関数従属とは、データベースのテーブル内で、ある列(属性)Xの値が決まれば、別の列Yの値が一意に定まる関係(X→Y)のこと。学生IDから氏名が、注文番号から商品名が決定する関係などがこれに当たり、正規化によるデータ整合性向上に不可欠な概念です。
関数従属の基本概念
- 決定項(X)と従属項(Y):
X→Yと表され、「XはYを決定する」「YはXに関数従属する」と読みます。
- 例: 「学生ID」が決まれば、「名前」や「学年」は一意に定まる(学生ID
→ 名前)。
- 目的: データベース設計における冗長性の排除(正規化)。
関数従属の種類
- 完全関数従属
- 主キー(複合キー)を構成するすべての属性の組み合わせによってのみ、他の属性が決定される関係。
- 例: 「{注文ID, 商品ID}
→ 数量」(数量は両方のキーが揃わないと特定できない)。
- 部分関数従属
- 主キーが複数の列(複合キー)で構成されるとき、その一部のみによって他の属性が決定される関係。
- 例: 「{注文ID, 商品ID}
→ 商品名」(商品IDだけで商品名が決まるため、「注文ID」に対して余分である)。
- 第2正規化で解消される。
- 推移的関数従属
- 主キー
X から Y
が決まり、その Y
からさらに Z
が決まる(X→Y→Z
)関係。
- 例: 「社員ID
→ 部署コード →
部署名」(社員IDから直接部署名が決まるが、部署コードを経由している)。
- 第3正規化で解消される。
- 主キー
非正規形
非正規形は、データベース設計においてデータが整理されておらず、同じ属性の項目が複数回繰り返されたり、1つのセルに複数のデータが存在する未整理の状態です。データ重複や不整合、削除・更新時のエラーが発生しやすい構造です。
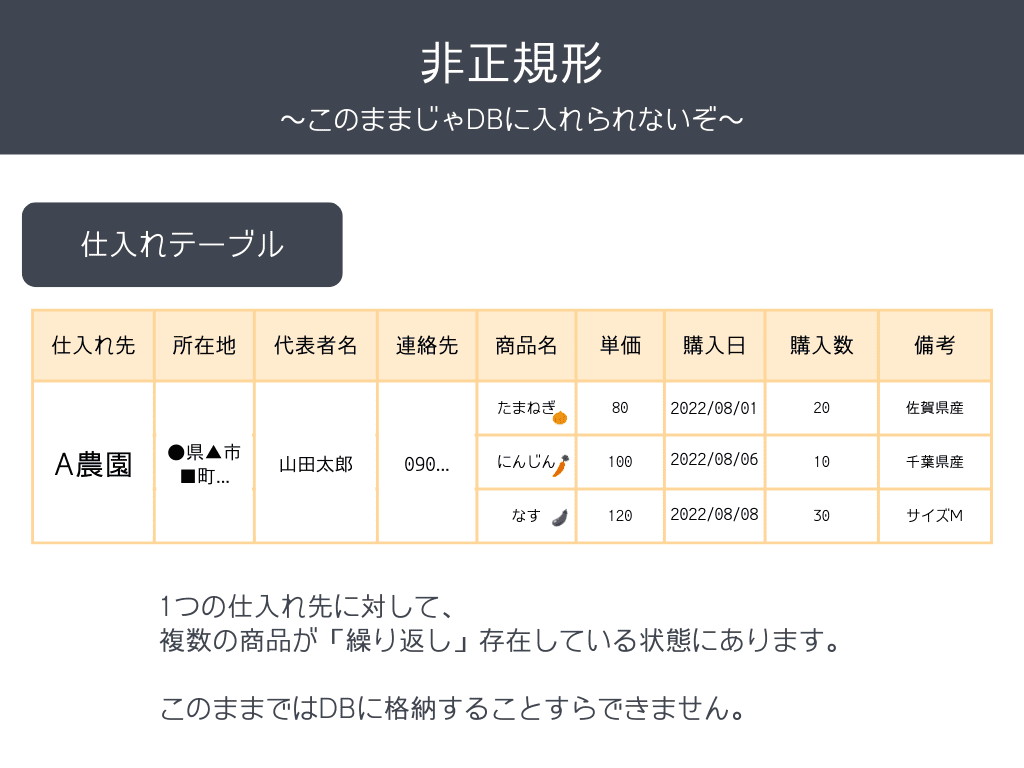
画像参照:https://tech-begin.com/computer-basic/database/normalize/
主な特徴とデメリット
- データの繰り返し: 1行の中に「商品1」「商品2」など同じ項目が並ぶ。
- 整合性の欠如: 同じ情報が複数の場所にあるため、修正漏れが起きやすい。
- 非効率: 1行の長さがバラバラで、データベースの管理(RDBMS)に適していない。
第1正規形
第1正規形(1NF)は、データベース設計の正規化における最初の段階で、テーブルの各セル(フィールド)が分割不可能な単一のスカラ値のみを持ち、繰り返し項目(グループ)を排除した状態です。1つの項目に複数データを含めたり、電話番号1・2のように列を分ける構造を、行を分けて整理します。
定義と主なルール
- 原子性: 全ての列は、それ以上分割できない単一の値(スカラ値)を持つ。
- 繰り返しグループの排除: 「商品名1、商品名2」のように列を繰り返さず、1レコード1データにする。
- 主キーの定義: 各レコードを一意に識別できる列(主キー)が存在する。
具体例
非正規形(繰り返しがある状態)を、1セル1値にして行を分割します。
【非正規形】(商品が複数の行に存在)
| 注文ID | 顧客名 | 商品(商品1, 商品2…) |
|---|---|---|
| 101 | 田中 | マウス, キーボード |
| 102 | 佐藤 | モニター |
【第1正規形】(1セル1値に整理)
| 注文ID | 顧客名 | 商品 |
|---|---|---|
| 101 | 田中 | マウス |
| 101 | 田中 | キーボード |
| 102 | 佐藤 | モニター |
メリット
- データの検索・更新が容易になる: カンマ区切りの文字列を分割する複雑なクエリが不要になる。
- 整合性の保持: 繰り返しデータによる不整合(データの矛盾)を防ぐ。
- RDBに適した構造: リレーショナルデータベース(RDB)の基本的なテーブル構造に適合する。
第1正規化の次は、主キーの一部に依存する項目を分離する「第2正規形」に進みます。
第2正規形
第2正規形(2NF)は、第1正規形のテーブルに対し、複合主キーの一部だけに依存する属性(部分関数従属)を別テーブルに分離する正規化です。これにより、データの冗長性や更新時の不整合を排除し、すべての非キー属性が主キー全体に完全に依存する状態(完全関数従属)にします。
主要なポイント
- 前提条件: 第1正規形(1NF)であること。
- 目的: 部分関数従属(主キーの一部で決定する項目)の排除。
- 対象: 2つ以上の属性からなる「複合主キー」を持つテーブル。
具体例と手続き
「受注テーブル(受注ID、商品ID、商品名、数量)」が複合主キー(受注ID、商品ID)を持つ場合、商品名は商品IDだけで決まるため、以下の通りテーブルを分割する。
- 受注詳細テーブル: (受注ID、商品ID、数量) ※主キー全体に依存
- 商品テーブル: (商品ID、商品名) ※主キー(商品ID)にのみ依存
メリット
- データ整合性: 商品名を変更しても、1箇所を更新するだけで済み、不整合が発生しない。
- 冗長性排除: 商品情報が重複して登録されることがなくなる。
第3正規形
第3正規形(3NF)は、第2正規化済みのテーブルから「推移的関数従属」を排除し、非主キー属性が主キーにのみ直接依存する状態のことです。具体的には、主キー以外の列(非キー属性)が、他の非キー属性によって決定される関係を別テーブルに分離することで、データの冗長性や更新時の不整合を防ぎます。
定義と目的
- 定義: 第2正規形を満たし、かつ、主キー以外の列間に依存関係(推移的関数従属)がない状態。
- 目的: データの冗長性を極小化し、更新・挿入・削除異常(データ不整合)を防止する。
推移的関数従属とは
「主キー → A → B」のように、主キー以外の列(A)が別の列(B)を決定している状態。
- 例:
{社員ID (主キー) -> 部署ID -> 部署名} - この場合、部署名が部署IDという「非キー」に依存しており、部署名変更時に複数行更新の必要があるため、第3正規形に違反します。
手順(例:社員テーブル)
- 非正規テーブル: 社員ID(PK), 社員名, 部署ID, 部署名
- 推移的従属の特定: 社員ID
→ 部署ID、部署ID →
部署名 となっており、部署名が主キー以外に依存。
- テーブルの分割:
- 社員テーブル: 社員ID(PK), 社員名, 部署ID
- 部署テーブル: 部署ID(PK), 部署名
この結果、部署名の変更は「部署テーブル」の1カ所のみで済み、データの一貫性が保たれます。
PK=プライマリーキー(主キー)
リレーショナルデータベース(RDB)のテーブルにおいて、各レコード(行)を1つに特定するための一意な識別子を指します。
主な特徴
- 非キー属性の独立: 主キー以外の列は、主キーにのみ関数従属する。
- テーブル数: 正規化を進めるほどテーブル数は増える傾向にある。
- データ構造: データの冗長性が排除され、整合性が高まる。
正規化の欠点と利点
正規化は、データの冗長性を排除して一貫性を保ち、更新不整合を防ぐ利点がある一方、テーブル数増加によるSQLの複雑化や、結合(JOIN)操作に伴う検索パフォーマンス低下という欠点があります。一般に第3正規形までを目安にし、状況に応じ非正規化も検討します。
正規化の利点(メリット)
- データ整合性の向上: データの重複を削除するため、データの挿入、更新、削除時に不整合(異常)が発生しにくくなる。
- ストレージ容量の節約: 無駄なデータ重複を省くことで、データベースの容量を効率化できる。
- 柔軟性と拡張性: テーブル構造が整理され、新しいデータ項目を追加する際などにシステム構造を変更しやすい。
- データ構造の明確化: テーブルの意味が明確になり、データベース設計が分かりやすくなる。
正規化の欠点(デメリット)
- 検索パフォーマンスの低下: データを複数のテーブルに分割するため、情報を取得する際にJOIN(結合)操作が頻繁に必要となり、検索速度が低下する。
- クエリの複雑化: JOINが必要になるため、SQL文が複雑になり、開発の難易度が上がる。
- 専門知識が必要: データベースの正規化に関する深い知識が必要となり、設計と運用の複雑さが増す。
正規化と非正規化の使い分け
データ整合性が重要なトランザクション処理(OLTP)では正規化を行い、検索速度が重視される分析処理(OLAP)や検索画面では、あえてデータを冗長に持つ「非正規化」を行うなど、システム要件に合わせて使い分けることが重要です。
知識に自信ができた方は、今度は自身のキャリアアップに向けて準備してみませんか?

まずは無料でキャリア相談

コメント