
アルゴリズムは問題を解決するための手順や方法論(料理のレシピ)、データ構造はデータを効率的に整理・格納する形式(食材の保管方法)を指します。また、これらはプログラミングの基礎であり、適切な組み合わせでプログラムの性能(速度や効率)を大幅に向上させるために不可欠です。データ構造(配列、リスト、木など)は「何を(データ)」、アルゴリズム(探索、ソートなど)は「どうする(手順)」を決め、両者は密接に連携し、効率的なソフトウェア開発と問題解決の鍵となります。

画像参照:https://mo-gu-mo-gu.com/about-datastructure-algorithm/
リスト(線形リスト)
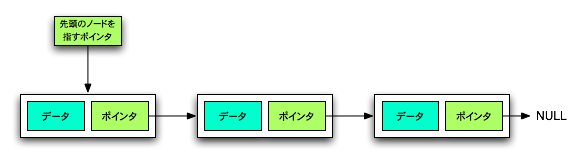
線形リストとは、データを「ノード」と呼ばれる箱に入れ、その箱が「ポインタ(参照情報)」で数珠つなぎに連結されたデータ構造で、配列と違いメモリ上で連続している必要がなく、要素の挿入・削除が容易なのが特徴です。各ノードはデータ本体と「次のノード」へのポインタを持ち、先頭からたどっていくことで順にデータにアクセスします。
画像参照:https://www.cc.kyoto-su.ac.jp/~yamada/ap/list.html
特徴と仕組み
- ノード:データを格納する部分と、次のノードを指し示すポインタ(アドレス情報)を持つ構造体のようなものです。
- ポインタ:次の要素のメモリ上の位置(アドレス)を指し示し、要素同士を繋ぎます。
- ヘッド(先頭ポインタ):リストの開始点(最初のノード)を指すポインタです。
- NULL(終端):リストの最後のノードのポインタは、何も指さない特別な値(NULL)になります。
- 線形:要素が一直線に連なっている状態を指します。
種類
画像参照:https://algo-logic.info/linked-list/
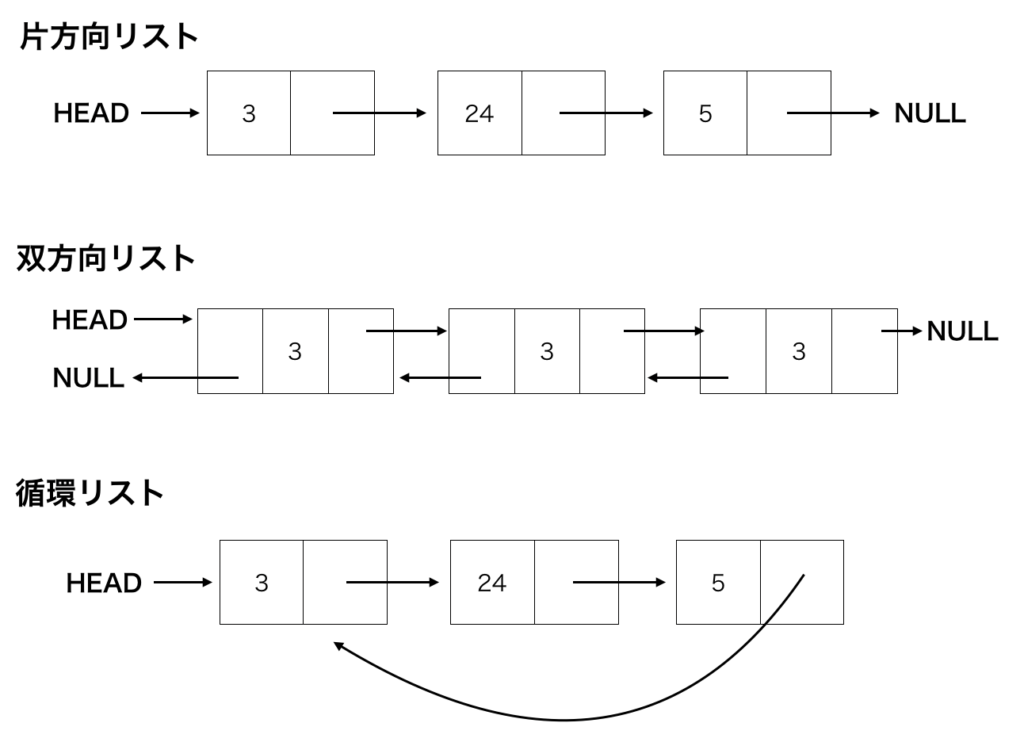
- 単方向リスト(片方向リスト):「次」の要素へのポインタのみを持ち、先頭から末尾へ一方向にしかたどれません。
- 双方向リスト:「次」と「前」の両方の要素へのポインタを持ち、双方向にたどれます。
- 循環リスト:末尾のノードが先頭のノードを指し、円環状に連結されています。先頭や末尾が存在しないとも言えます。
配列との違いとメリット・デメリット
- 配列:メモリ上に連続して配置され、ランダムアクセス(任意の位置へのアクセス)は速いですが、途中に要素を挿入・削除する際に大量のデータ移動(コピー)が必要になります。
- 線形リスト:メモリは連続でなくてもよく、ポインタの付け替えだけで要素の挿入・削除ができるため、動的なデータ管理(頻繁な追加・削除)に向いています。しかし、特定の要素を見つけるための検索(探索)は先頭から順にたどる必要があるため、配列より遅くなることがあります。
主な用途
- スタックやキューといった基本的なデータ構造の実装。
- ファイルのディレクトリ構造(フォルダ内のファイル一覧など)。
- データの順序を保持しつつ、動的な追加・削除が頻繁に発生する場面。
スタック
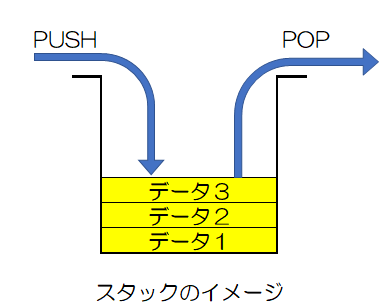
スタックは、データを「後入れ先出し(LIFO)」のルールで出し入れするデータ構造で、積み重ねた皿や本のように最後に入れたものが最初に取り出されるのが特徴です。データを「プッシュ(PUSH)」で追加し、「ポップ(POP)」で一番上(最後に入れたもの)から取り出し、「戻るボタン」や「関数呼び出しの管理」などに使われます。
特徴と操作
- LIFO : 後から入れたデータが先に出てくる方式。
- プッシュ(PUSH) : スタックの「一番上(トップ)」にデータを追加する操作。
- ポップ(POP): スタックの「一番上(トップ)」からデータを一つ取り出す操作。
身近な例え
- 積み重ねた皿: 一番上から取り出す。
- エレベーター: 後に乗った人が先に降りる。
- Webブラウザの戻るボタン: 直前のページ(最後に追加された履歴)に戻る。
応用例
- 関数呼び出し(コールスタック): 関数が呼び出された順序で処理(一時データの退避や戻りアドレスの管理)を行う。
- テキストエディタの「元に戻す」機能: 変更履歴をスタックに積んで、逆順に解除する。
- 数式の逆ポーランド記法の評価。
キュー
キューは、先入れ先出し(FIFO)の原則に基づいてデータを管理する、基本的なデータ構造です。人が窓口で並ぶ待ち行列のように、最初に入れたデータが最初に取り出され、新しいデータは必ず末尾に追加され、取り出しは常に先頭から行われます。プログラミングでは、タスクの処理待ち(プリンタ、CPUなど)やメッセージの管理などに利用されます。

画像参照:https://medium-company.com/queue/
キューの基本動作
- エンキュー : キューの末尾(後ろ)にデータを追加します。
- デキュー : キューの先頭(前)からデータを取り出します。
特徴と例
- FIFO : 先に入ったものが先に出るという原則。
- 待ち行列: スーパーのレジ、銀行の窓口、電話の問い合わせ窓口などが例えられます。
- コンピュータでの利用:
- 印刷ジョブの管理: 印刷要求を順番に処理。
- タスクスケジューリング: CPUが処理するタスクの待ち行列。
- イベント処理: ウィンドウシステムでのメッセージ処理。
実装方法
- 配列: メモリ効率が良い反面、操作(特に削除時)でデータ移動が必要になり、効率が悪い場合があります。
- 連結リスト: データ量の変動に柔軟に対応でき、メモリ効率が高いですが、ポインタ操作で設計が複雑になることがあります
連結リスト
データと次の要素へのポインタ(参照)をセットにした「ノード」を、メモリ上で論理的につなげたデータ構造です。
例:単方向リスト(方方向リスト)、双方向リスト、循環リスト
押さえておきたいポイント
リスト
データを順番に並べて管理する構造です。
各要素には前後関係があります。
▶︎要点
- 要素の追加・削除・探索を行う
- 配列と違い、途中への挿入・削除がしやすい(連結リストの場合)
- 各要素が次の要素への参照(ポインタ)を持つことがある
▶︎よく出る用語
- 単方向リスト:次の要素だけを指す
- 双方向リスト:前後両方を指す
- 循環リスト:最後の要素が先頭を指す
▶︎試験での注意
- 探索は先頭から順にたどることが多い
- 途中の要素を探すには時間がかかる
スタック
後入れ先出し(LIFO: Last In, First Out) の構造です。
最後に入れたものを最初に取り出します。
▶︎基本操作
- push:データを積む
- pop:データを取り出す
▶︎イメージ
本の積み重ね。上に置いて上から取る。
▶︎利用例
- 関数呼び出し(コールスタック)
→プログラムの実行中に現在どの関数が動作中で、次にどこへ戻るべきかを管理する「後入れ先出し(LIFO: Last-In, First-Out)」のメモリ領域です。 - 括弧の対応チェック
→開き括弧「(」「{」「[」と閉じ括弧「)」「}」「]」の数と順序が一致しているかを確認する作業です。 - 深さ優先探索(DFS)
→グラフや木構造において、可能な限り深く(末端まで)探索を進め、行き止まりになったら1つ前の分岐点に戻って別の枝を探索するアルゴリズムです。
▶︎試験でよく問われること
例えば 1 → 2 → 3 の順に push したら、取り出し順は 3 → 2 → 1
キュー
先入れ先出し(FIFO: First In, First Out) の構造です。
先に入れたものを先に取り出します。
▶︎基本操作
- enqueue:末尾に追加
- dequeue:先頭から取り出す
▶︎イメージ
レジ待ちの列。
▶︎利用例
- プリンタの印刷待ち
- OSのジョブ管理
- 幅優先探索(BFS)
→グラフや木構造において、開始ノードから近い順(階層順)に探索を進めるアルゴリズムです。
▶︎試験でよく問われること
例えば 1 → 2 → 3 の順に enqueue したら、取り出し順は 1 → 2 → 3
ここはよく比較される
| 項目 | スタック | キュー |
|---|---|---|
| 取り出し | 後入れ先出し | 先入れ先出し |
| 英語 | LIFO | FIFO |
| 追加位置 | 先頭(上) | 末尾 |
| 取り出し位置 | 先頭(上) | 先頭 |
応用情報でよく出るひっかけ
- push / pop / enqueue / dequeue の意味を混同しない
- 処理後の並び順を問う問題が多い
- 深さ優先探索(DFS) はスタック、幅優先探索(BFS) はキュー
試験で最短で覚えるならこの3つ
- リスト:順番付きデータの管理
- スタック:後入れ先出し(LIFO)
- キュー:先入れ先出し(FIFO)
知識に自信ができた方は、今度は自身のキャリアアップに向けて準備してみませんか?

まずは無料でキャリア相談

コメント